
Search engine bots (also known as bots) are programs that automatically browse websites. These programs are used to crawl the site’s content that is then used for search or other actions. At first, this may seem like a good thing, but not all of those programs are good. Sometimes, those programs can be harmful. For example, they harvest email, do web scraping, and do other stuff. They can also cause your site’s load when the site is visited by either many different bots at once or one that generates many queries at once. However, you as a site’s owner can create a robots.txt file that provides instructions (Robots Exclusion Protocol) specifically for these visitors.
Where can I find my robots.txt file?
You can find the robots.txt file in the public_html folder of your site. Login to your cPanel and pick File Manager

Enter public_html folder
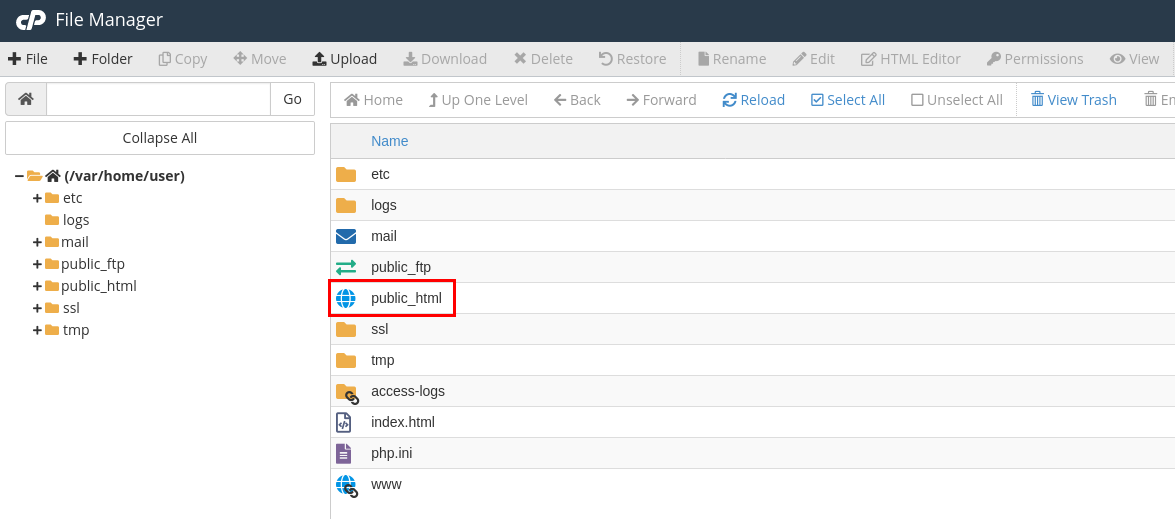
Check if the robots.txt file exists. If it does, right-click on the file and pick Edit
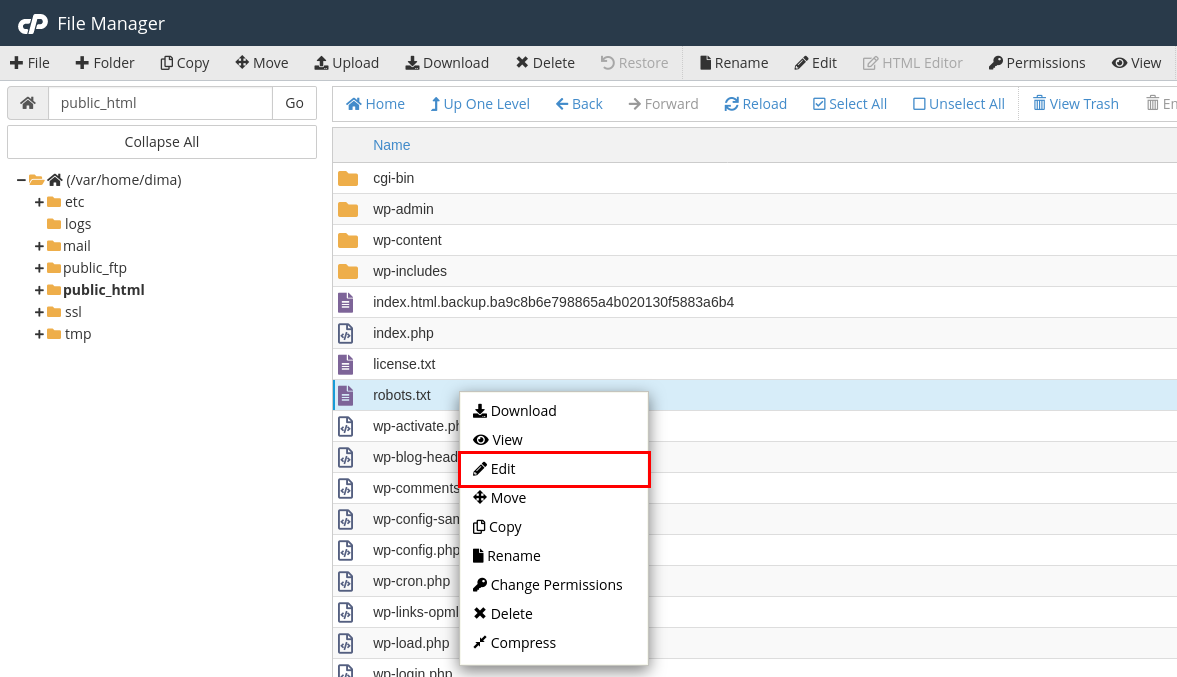
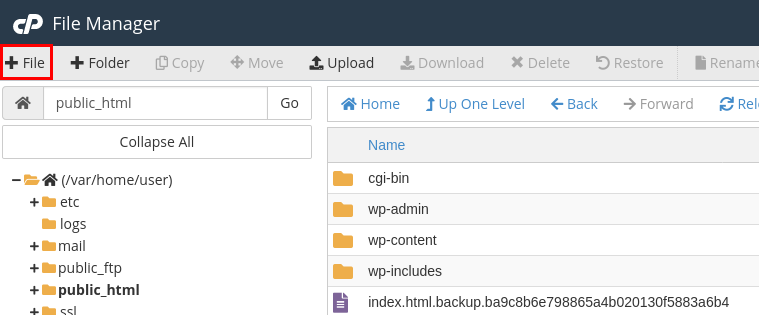
If the file does not exist, you can create it by clicking + File on the left-right corner of your File Manager
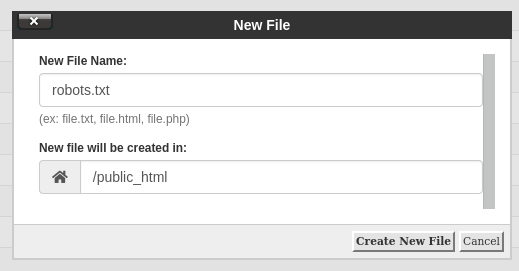
Creating rules in a robots.txt file
All robots have access to all parts of the site (also works if robots.txt is empty or missing):
User-agent: * Disallow: /
One robot is prohibited from indexing the site, all others are allowed. Note that when you enter multiple instructions, they are separated by a single space:
User-agent: robot_name Disallow: / User-agent: * Disallow:
Queries for one particular robot are slowed down to 1 query every 10 seconds:
User-agent: robot_name Crawl-delay: 10
All robots are prohibited from accessing only two directories:
User-agent: * Disallow: /temp/ Disallow: /include/
All robots are not allowed to access one file:
User-agent: * Disallow: /folder/file.html
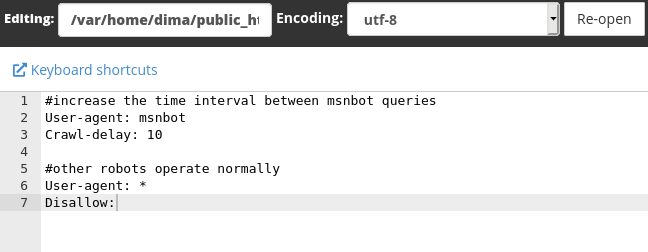
An example of a robots.txt file can look like this:
How do I evaluate which robots are crawling my site?
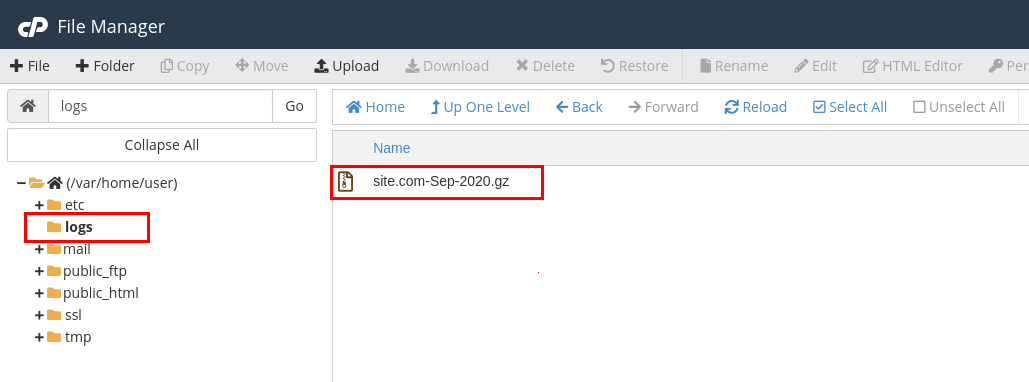
This can be done by checking the Apache log of your server. You can find the Apache log in your cPanel File Manager (/var/home/user/log)
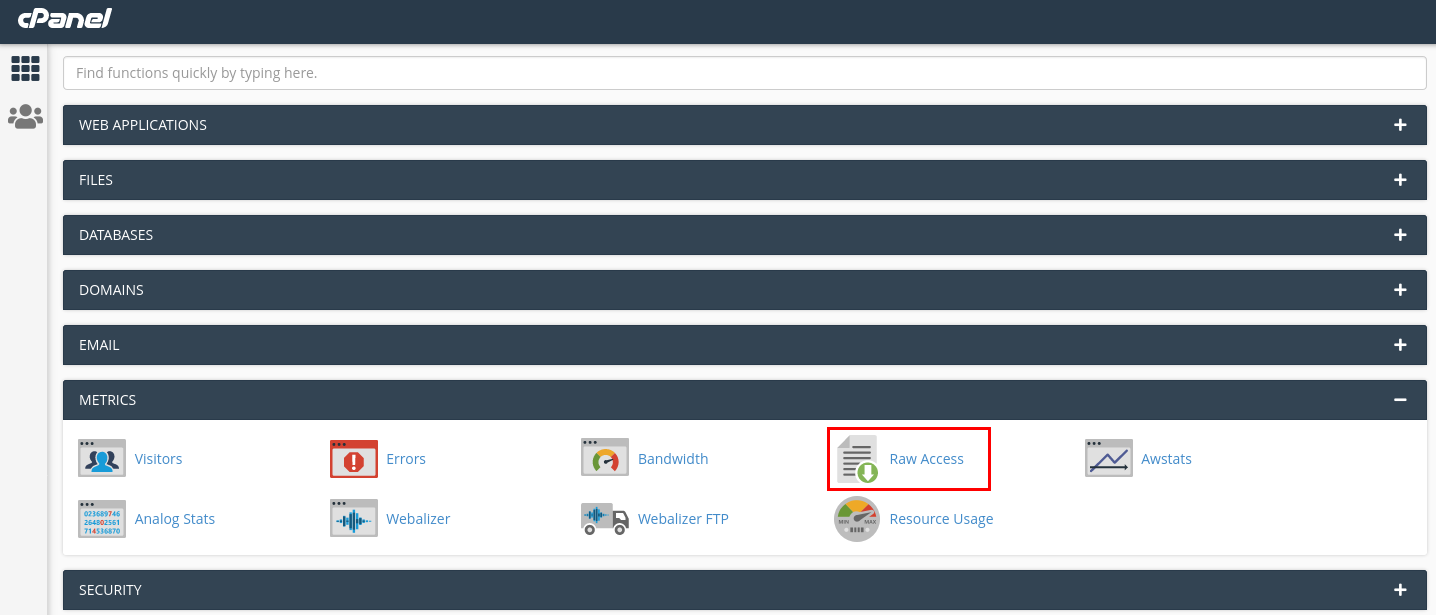
If you need the latest entries, you can check the Raw Access section
Unzip the downloaded file on your PC and open it with a text editor. Use the search in the text editor (Ctrl + F) and try to find the value of ‘Bot‘. The search will give you results where you can see which robots have crawled your site.
In this example, you can see Google Bot entries.

Additional information
Some search engines, such as Google also have an option to manage the Googlebot crawl rate. Meaning, that you can limit the crawl rate directly via Google. You can find more information on the page below:
https://support.google.com/webmasters/answer/48620?hl=en
Information about Bing crawl control can be found here:
https://www.bing.com/webmaster/help/crawl-control-55a30302
Check this page to see a list of malicious Bots:
http://www.botreports.com/badbots/index.shtml
Conclusion
As mentioned at the beginning, not all queries may be useful for your site. There are scrapers, spambots, email harvesters, and more bots that you don’t want on your site. In other cases, bots themselves might be doing a good thing, however, your plan’s resources are too low to handle multiple requests at once.
So in order to optimize a site’s performance, it is worth evaluating which search engines will be useful for your site and which will not.